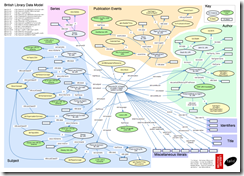
Open Data: Digital Fuel or Raw Material?
I have been reading with interest ‘Digital Fuel of the 21st Century: Innovation through Open Data and the Network Effect’ by Vivek Kundra. Well worth a read to place the current [Digital] Revolution we are somewhere in the middle of, in relation to preceding revolutions and the ages that they begat.