
A Discovery Opportunity for Archives?
So why am I now suggesting that there maybe an opportunity for the discovery of archives and their resources?
Check out our new fixed price service to find out how your site is performing!
So why am I now suggesting that there maybe an opportunity for the discovery of archives and their resources?
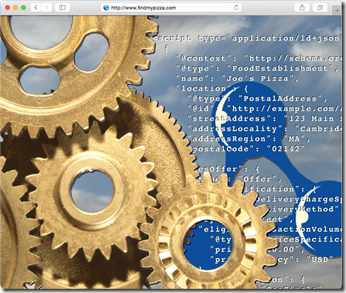
Let me explain what is this fundamental component of what I am seeing potentially as a New Web, and what I mean by New Web.
This fundamental component I am talking about you might be surprised to learn is a vocabulary – Schema.org.

A bit of a profound question – triggered by a guest post on Museums Computer Group by Nick Poole CEO of The Collections Trust about Culture Grid and an overview of recent announcements about it. Broadly the changes are that: The Culture Grid closed to ‘new accessions’ (ie. new collections of metadata) on the 30th April The existing index and API will continue to operate in order to ensure legacy support Museums, galleries, libraries and archives wishing to contribute material to Europeana can still do so via the ‘dark aggregator’, which the Collections Trust will continue to fund Interested parties …

About a month ago Version 2.0 of the Schema.org vocabulary hit the streets. But does this warrant the version number clicking over from 1.xx to 2.0?

Several significant bibliographic related proposals were brought together in a package which I take great pleasure in reporting was included in the latest v1.9 release of Schema.org

They’re released! A couple of months back I spoke about the preview release of Works data from WorldCat.org. Today OCLC published a press release announcing the official release of 197 million descriptions of bibliographic Works. A Work is a high-level description of a resource, containing information such as author, name, descriptions, subjects etc., common to all editions of the work. The description format is based upon some of the properties defined by the CreativeWork type from the Schema.org vocabulary. In the case of a WorldCat Work description, it also contains [Linked Data] links to individual, OCLC numbered, editions already shared …
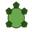
One of the most challenging challenges in my evangelism of the benefits of using Schema.org for sharing data about resources via the web is that it is difficult to ‘show’ what is going on. The scenario goes something like this….. “Using the Schema.org vocabulary, you embed data about your resources in the HTML that makes up the page using either microdata or RDFa….” At about this time you usually display a slide showing html code with embedded RDFa. It may look pretty but the chances of more than a few of the audience being able to pick out the schema:Book …
demonstrating on-going progress towards implementing the strategy, I had the pleasure to preview two upcoming significant announcements on the WorldCat data front: 1. The release of 194 Million Linked Data Bibliographic Work descriptions. 2. The WorldCat Linked Data Explorer interface
The Getty Research Institute has announced the release of the Art & Architecture Thesaurus (AAT)® as Linked Open Data. The data set is available for download at vocab.getty.edu under an Open Data Commons Attribution License (ODC BY 1.0). The Art & Architecture Thesaurus is a reference of over 250,000 terms on art and architectural history, styles, and techniques. I’m sure this will become an indispensible authoritative hub of terms in the Web of Data to assist those describing their resources and placing them in context in that Web. This is the fist step in an 18 month process to release …

Little things mean a lot. Little things that are misunderstood often mean a lot more. Take the OCLC Control Number, often known as the OCN, for instance. Every time an OCLC bibliographic record is created in WorldCat it is given a unique number from a sequential set – a process that has already taken place over a billion times. The individual number can be found represented in the record it is associated with. Over time these numbers have become a useful part of the processing of not only OCLC and its member libraries but, as a unique identifier proliferated across …