One of the most challenging challenges in my evangelism of the benefits of using Schema.org for sharing data about resources via the web is that it is difficult to ‘show’ what is going on.
The scenario goes something like this…..
“Using the Schema.org vocabulary, you embed data about your resources in the HTML that makes up the page using either microdata or RDFa….”
At about this time you usually display a slide showing html code with embedded RDFa. It may look pretty but the chances of more than a few of the audience being able to pick out the schema:Book or sameAs or rdf:type elements out of the plethora  of angle brackets and quotes swimming before their eyes is fairly remote.
of angle brackets and quotes swimming before their eyes is fairly remote.
Having asked them to take a leap of faith that the gobbledegook you have just presented them with, is not only simple to produce but also invisible to users viewing their pages – “but not to Google, which harvest that meaningful structured data from within your pages” – you ask them to take another leap [of faith].
You ask them to take on trust that Google is actually understanding, indexing and using that structured data. At this point you start searching for suitable screen shots of Google Knowledge Graph to sit behind you whilst you hypothesise about the latest incarnation of their all-powerful search algorithm, and how they imply that they use the Schema.org data to drive so-called Semantic Search.
I enjoy a challenge, but I also like to find a better way sometimes. w3
![]() When OCLC first released Linked Data in WorldCat they very helpfully addressed the first of these issues
When OCLC first released Linked Data in WorldCat they very helpfully addressed the first of these issues 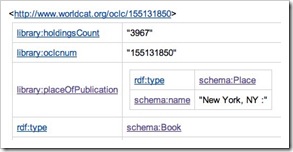 by adding a visual display of the Linked Data to the bottom of each page. This made my job far easier!
by adding a visual display of the Linked Data to the bottom of each page. This made my job far easier!
But it has a couple of downsides. Firstly it is not the prettiest of displays and is only really of use to those interested in ‘seeing’ Linked Data. Secondly, I believe it creates an impression to some that, if you want Google to grab structured data about resources, you need to display a chunk of gobbledegook on your pages.
![]() Let the Green Turtle show the way!
Let the Green Turtle show the way!
Whilst looking for a better answer I discovered Green Turtle – a JavaScript library for working with RDFa and most usefully packaged in an extention for the Chrome browser. Load this into your copy of Chrome and it will sit quietly in the background checking for RDFa (and microdata if you turn on the option) in the pages you are viewing. When it finds one, a green turtle icon![]() appears in the address bar.
appears in the address bar.  Clicking on that turtle opens up a new tab to show you a list of the data, in the form of triples, that it identified within the page.
Clicking on that turtle opens up a new tab to show you a list of the data, in the form of triples, that it identified within the page.
That simple way to easily show someone the data embedded in a page, is a great aid to understanding for those new to the concept. But that is not all. This excellent little extension has a couple of extra tricks up its sleeve.
 It includes a visualisation of the [Linked Data] graph of relationships – the structure of the data. Clicking on any of the nodes of the display, causes the value of the subject, predicate, or object it represents to be displayed below the image and the relevant row(s) in the list of triples to be highlighted. As well as all this, there is a ‘Show Turtle’ button, which does just as you would expect opening up a window in which it has translated the triples into Turtle – Turtle being (after a bit of practise) the more human friendly way of viewing or creating RDF.
It includes a visualisation of the [Linked Data] graph of relationships – the structure of the data. Clicking on any of the nodes of the display, causes the value of the subject, predicate, or object it represents to be displayed below the image and the relevant row(s) in the list of triples to be highlighted. As well as all this, there is a ‘Show Turtle’ button, which does just as you would expect opening up a window in which it has translated the triples into Turtle – Turtle being (after a bit of practise) the more human friendly way of viewing or creating RDF.
Green Turtle is a useful little tool which I would recommend to visualise microdata and RDFa, be it using the Schema.org vocabulary or not. I am already using it on WorldCat in preference to scrolling to the bottom of the page to click the Linked Data tab.
![]() Custom Searches that know about Schema!
Custom Searches that know about Schema!
Google have recently enhanced the functionality of their Custom Search Engine (CSE) to enable searching by Schema.org Types. Try out this example CSE which only returns results from WorldCat.org which have been described in their structured data as being of type schema:Book.
[raw_html_snippet id=”my_search_worldcat_books”]
A simple yet powerful demonstration that not only are Google harvesting the Schema.org Linked Data from WorldCat, but they are also understanding it and are visibly using it to drive functionality.
RT @DataLiberate: Visualising http://t.co/415kzBgBDR: Seeing your triples and showing Google using them: http://t.co/qyWOIslPRU #linkeddat…
RT @DataLiberate: Visualising http://t.co/415kzBgBDR: Seeing your triples and showing Google using them: http://t.co/qyWOIslPRU #linkeddat…
@DataLiberate Visualising http://t.co/CSKCOKlBBG: Seeing your triples and showing Google using them http://t.co/cpJOJG3S15 cc @alexmilowski
Visualising #schema.org – http://t.co/I6tGP4N3Zb @rjw
RT @aaranged: Visualising #schema.org – http://t.co/I6tGP4N3Zb @rjw
RT @aaranged: Visualising #schema.org – http://t.co/I6tGP4N3Zb @rjw
Visualising http://t.co/wsHdj8EsVd http://t.co/mTCe9DbVJD
RT @aaranged: Visualising #schema.org – http://t.co/I6tGP4N3Zb @rjw
RT @aaranged: Visualising #schema.org – http://t.co/I6tGP4N3Zb @rjw
Visualizing http://t.co/ngu9ldgPuY http://t.co/0zFlrAs9dR
Visualising http://t.co/o9pQ46YYeq http://t.co/T1c1jWb260
RT @DataLiberate: Visualising http://t.co/415kzBgBDR: Seeing your triples and showing Google using them: http://t.co/qyWOIslPRU #linkeddat…
“@aaranged: Visualising #schema.org – http://t.co/D4AaRBJuuP @rjw”
Visualising http://t.co/PReiNnWgjc http://t.co/ejDLPgsd1B
RT @ALA_TechSource: Visualising http://t.co/PReiNnWgjc http://t.co/ejDLPgsd1B
RT @ALA_TechSource: Visualising http://t.co/PReiNnWgjc http://t.co/ejDLPgsd1B
RT @DataLiberate: Visualising http://t.co/415kzBgBDR: Seeing your triples and showing Google using them: http://t.co/qyWOIslPRU #linkeddat…
RT @DataLiberate: Visualising http://t.co/415kzBgBDR: Seeing your triples and showing Google using them: http://t.co/qyWOIslPRU #linkeddat…
RT @DataLiberate: Visualising http://t.co/415kzBgBDR: Seeing your triples and showing Google using them: http://t.co/qyWOIslPRU #linkeddat…