Is There Still a Case for Aggregations of Cultural Data

A bit of a profound question – triggered by a guest post on Museums Computer Group by Nick Poole CEO of The Collections Trust about Culture Grid and an overview of recent announcements about it. Broadly the changes are that: The Culture Grid closed to ‘new accessions’ (ie. new collections of metadata) on the 30th April The existing index and API will continue to operate in order to ensure legacy support Museums, galleries, libraries and archives wishing to contribute material to Europeana can still do so via the ‘dark aggregator’, which the Collections Trust will continue to fund Interested parties …
Read More ...Schema.org 2.0

About a month ago Version 2.0 of the Schema.org vocabulary hit the streets. But does this warrant the version number clicking over from 1.xx to 2.0?
Read More ...The role of Role in Schema.org

This post is about an unusual, but very useful, aspect of the Schema.org vocabulary — the Role type.
Read More ...Google Sunsets Freebase – Good News For Wikidata?

Google announced yesterday that it is the end of the line for Freebase – will this be good for Wikidata?
Read More ...Baby Steps Towards A Library Graph

It is one thing to have a vision, regular readers of this blog will know I have them all the time, its yet another to see it starting to form through the mist into a reality. Several times in the recent past I have spoken of the some of the building blocks for bibliographic data to play a prominent part in the Web of Data. The Web of Data that is starting to take shape and drive benefits for everyone. Benefits that for many are hiding in plain site on the results pages of search engines. In those informational panels …
Read More ...A Step for Schema.org – A Leap for Bib Data on the Web

Several significant bibliographic related proposals were brought together in a package which I take great pleasure in reporting was included in the latest v1.9 release of Schema.org
Read More ...WorldCat Works – 197 Million Nuggets of Linked Data

They’re released! A couple of months back I spoke about the preview release of Works data from WorldCat.org. Today OCLC published a press release announcing the official release of 197 million descriptions of bibliographic Works. A Work is a high-level description of a resource, containing information such as author, name, descriptions, subjects etc., common to all editions of the work. The description format is based upon some of the properties defined by the CreativeWork type from the Schema.org vocabulary. In the case of a WorldCat Work description, it also contains [Linked Data] links to individual, OCLC numbered, editions already shared …
Read More ...Visualising Schema.org
One of the most challenging challenges in my evangelism of the benefits of using Schema.org for sharing data about resources via the web is that it is difficult to ‘show’ what is going on. The scenario goes something like this….. “Using the Schema.org vocabulary, you embed data about your resources in the HTML that makes up the page using either microdata or RDFa….” At about this time you usually display a slide showing html code with embedded RDFa. It may look pretty but the chances of more than a few of the audience being able to pick out the schema:Book …
Read More ...WorldCat Works Linked Data – Some Answers To Early Questions
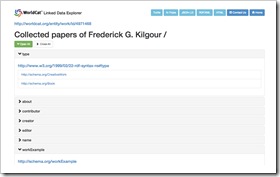
Since announcing the preview release of 194 Million Open Linked Data Bibliographic Work descriptions from OCLC’s WorldCat, last week at the excellent OCLC EMEA Regional Council event in Cape Town; my in-box and Twitter stream have been a little busy with questions about what the team at OCLC are doing. Instead of keeping the answers within individual email threads, I thought they may be of interest to a wider audience: Q I don’t see anything that describes the criteria for “workness.” “Workness” definition is more the result of several interdependent algorithmic decision processes than a simple set of criteria. To …
Read More ...OCLC Preview 194 Million Open Bibliographic Work Descriptions
demonstrating on-going progress towards implementing the strategy, I had the pleasure to preview two upcoming significant announcements on the WorldCat data front: 1. The release of 194 Million Linked Data Bibliographic Work descriptions. 2. The WorldCat Linked Data Explorer interface
Read More ...Getty Release AAT Vocabulary as Linked Open Data
The Getty Research Institute has announced the release of the Art & Architecture Thesaurus (AAT)® as Linked Open Data. The data set is available for download at vocab.getty.edu under an Open Data Commons Attribution License (ODC BY 1.0). The Art & Architecture Thesaurus is a reference of over 250,000 terms on art and architectural history, styles, and techniques. I’m sure this will become an indispensible authoritative hub of terms in the Web of Data to assist those describing their resources and placing them in context in that Web. This is the fist step in an 18 month process to release …
Read More ...OCLC Declare OCLC Control Numbers Public Domain

Little things mean a lot. Little things that are misunderstood often mean a lot more. Take the OCLC Control Number, often known as the OCN, for instance. Every time an OCLC bibliographic record is created in WorldCat it is given a unique number from a sequential set – a process that has already taken place over a billion times. The individual number can be found represented in the record it is associated with. Over time these numbers have become a useful part of the processing of not only OCLC and its member libraries but, as a unique identifier proliferated across …
Read More ...Content-Negotiation for WorldCat

I am pleased to share with you a small but significant step on the Linked Data journey for WorldCat and the exposure of data from OCLC. Content-negotiation has been implemented for the publication of Linked Data for WorldCat resources. For those immersed in the publication and consumption of Linked Data, there is little more to say. However I suspect there are a significant number of folks reading this who are wondering what the heck I am going on about. It is a little bit techie but I will try to keep it as simple as possible. Back last year, a …
Read More ...Putting Linked Data on the Map
Show me an example of the effective publishing of Linked Data – That, or a variation of it, must be the request I receive more than most when talking to those considering making their own resources available as Linked Data, either in their enterprise, or on the wider web. Ordnance Survey have built such an example.
Read More ...SemanticWeb.com Spotlight on Library Innovation

Help spotlight library innovation and send a library linked data practitioner to the SemTechBiz conference in San Francisco, June 2-5
Read More ...From Records to a Web of Library Data – Pt3 Beacons of Availability
As is often the way, you start a post without realising that it is part of a series of posts – as with the first in this series. That one – Entification, the following one – Hubs of Authority and this, together map out a journey that I believe the library community is undertaking as it evolves from a record based system of cataloguing items towards embracing distributed open linked data principles to connect users with the resources they seek. Although grounded in much of the theory and practice I promote and engage with, in my role as Technology Evangelist …
Read More ...From Records to a Web of Library Data – Pt2 Hubs of Authority

As is often the way, you start a post without realising that it is part of a series of posts – as with the first in this series. That one – Entification, and the next in the series – Beacons of Availability, together map out a journey that I believe the library community is undertaking as it evolves from a record based system of cataloguing items towards embracing distributed open linked data principles to connect users with the resources they seek. Although grounded in much of the theory and practice I promote and engage with, in my role as Technology …
Read More ...From Records to a Web of Library Data – Pt1 Entification

The phrase ‘getting library data into a linked data form’ hides multitude of issues. There are some obvious steps such as holding and/or outputting the data in RDF, providing resources with permanent URIs, etc. However, deriving useful library linked data from a source, such as a Marc record, requires far more than giving it a URI and encoding what you know, unchanged, as RDF triples.
Read More ...Forming Consensus on Schema.org for Libraries and More

Back in September I formed a W3C Group – Schema Bib Extend. To quote an old friend of mine “Why did you go and do that then?” Well, as I have mentioned before Schema.org has become a bit of a success story for structured data on the web. I would have no hesitation in recommending it as a starting point for anyone, in any sector, wanting to share structured data on the web. This is what OCLC did in the initial exercise to publish the 270+ million resources in WorldCat.org as Linked Data. At the same time, I believe that …
Read More ...The Correct End Of Your Telescope – Viewing Schema.org Adoption

I have been banging on about Schema.org for a while. For those that have been lurking under a structured data rock for the last year, it is an initiative of cooperation between Google, Bing, Yahoo!, and Yandex to establish a vocabulary for embedding structured data in web pages to describe ‘things’ on the web. Apart from the simple significance of having those four names in the same sentence as the word cooperation, this initiative is starting to have some impact. As I reported back in June, the search engines are already seeing some 7%-10% of pages they crawl containing Schema.org …
Read More ...